It’s also a business decision. Many times companies will massage their verbiage and have a plan in place before they even change the status to “investigating” simply to appease when they have SLAs. It’s stupid, but that’s often the reason.
Maybe somehow the problem was triggered in a way that the status page didn’t automatically detect it (for example, mine still works)? I’m really grasping at straws with that one. If it isn’t automatic, it categorically needs to be; if it is automatic but missed what’s apparently a major outage, then it needs to be fixed.

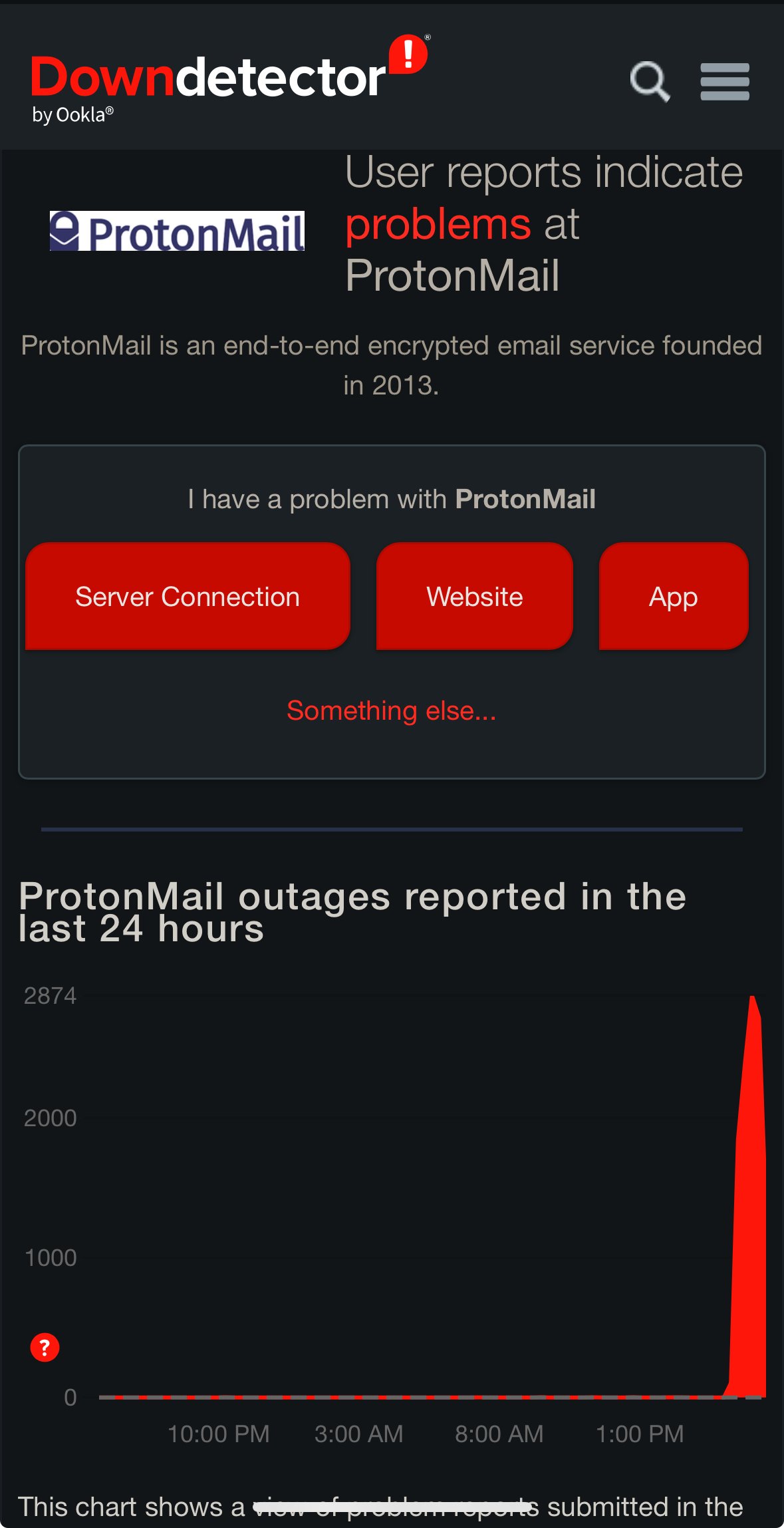{kind=link}
Why does a status page need to be updated manually?
Servers could still be up and responding to pings, yet backend databases could be down.
Or it could be a caching problem with the status service.
It’s bad ways of handling your status page but it happens.
There’s also a insurmountable amount of potential issues to cover, not worth the automation
It depends on the services, but in the end it’s pretty easy to spoof handshake packets to see if a service on a server is still running.
nmap is a great example.
It’s also a business decision. Many times companies will massage their verbiage and have a plan in place before they even change the status to “investigating” simply to appease when they have SLAs. It’s stupid, but that’s often the reason.
Maybe somehow the problem was triggered in a way that the status page didn’t automatically detect it (for example, mine still works)? I’m really grasping at straws with that one. If it isn’t automatic, it categorically needs to be; if it is automatic but missed what’s apparently a major outage, then it needs to be fixed.