
In Finnish, I can simply ask, “Juoksenneltaisiinko?” whereas in English, I have to say, “Should we run around aimlessly?”
Is that a common question to be asked in Finland?
Depends on how good drugs you’ve got
Traipse?
That’s the full sentence asking if you want to run around aimlessly.
Interesting word, I hadn’t heard of that one before. While not exactly perfect translation, it seems like a similar kind of word nevertheless. Doesn’t exactly seem to refer to running directly though.
I guess that in the case of my example, it’s more of a demonstration of how weirdly Finnish language can work. Juosta = run, juoksennella = run around aimlessly, juoksenneltaisiinko? = should we run around aimlessly?
Frolic?
Not the same thing. The complete sentence in English would be “do you want to frolic with me?”, which in Finnish is mashed together in a single word as the example given above. The chaining is something like “frolic-aimlessly-us-youwanna?”, though not by words but by endings.
It’s a similar story for Swedish and German for example. Not exactly the same as Finnish, but the whole mashing words together for them to make better sense. I’m starting to think that English is the odd one out.
One example could be “kommunikationsdepartementssekretariatsanteckningar” (communication department secretary’s notes). But an English example would be where Swedish, German, I guess Finnish, would say “blackboard” instead of “black board” to remove the ambiguity while English mostly does the latter.
Compound words are very different than agglutinative conjugation though. In such languages, you don’t just mash words together, you also modify them to encode all sorts of extra information into one word. You can form full, grammatically correct sentences that way. Can’t do that with compound words because you can’t compound them into a complete sentence.
A famous, powe example is the word “çekoslovakyalılaştırabildiklerimizdensiniz” from Turkish, which is like Finnish in that regard. It’s a complete sentence that means “you are one of those who we have managed to make a czechoslovakian”. The object, subject, verb, tense, and more are all in there. Obviously that’s quite a bit more complex than word together-mashing.
Yeah but no-one would ever really use a word like that. It’s just the example given in all memes, but a a more realistic one than epäjärjestelmällistyttämättömyydellänsäkäänköhään. I think it would be more probable that in that scenario, a Finn might say something like “pitäiskö juoksennella vähäse?”
But it is a good feature we have, yeah. Imagine trying to learn all those, whereas now they just come more or less naturally. (For that wordmonster, it takes a bit of concentration and I’m still unsure whether I typoed or not but whatever.)
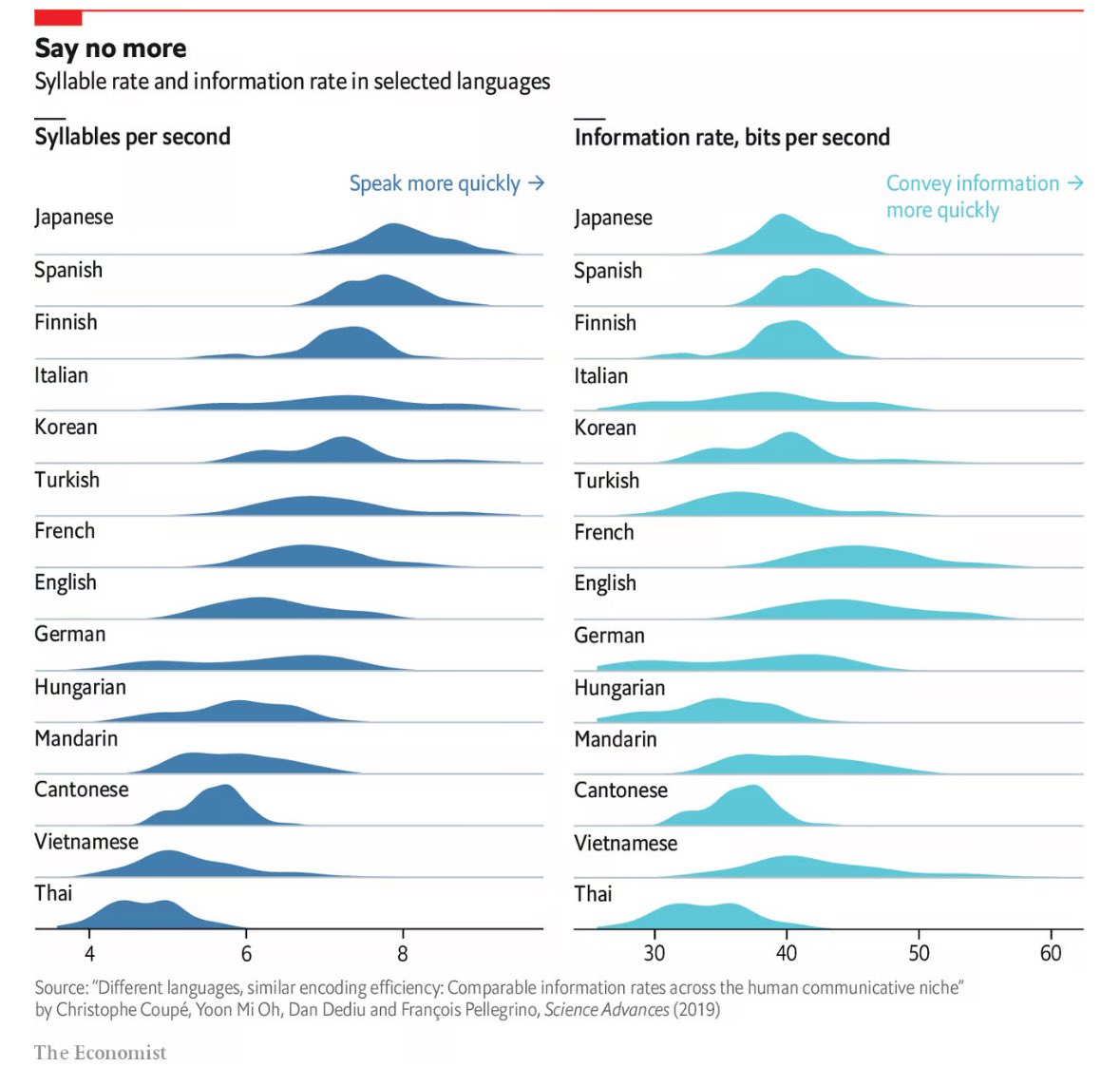
English is pictured as such a smooth, almost perfectly normalized bell curve. On one hand it’s such a versatile language that (largely due to colonialism) has undergone so much evolution and mixing with other languages that I can believe that. On the other hand it looks almost too normal. Odd.
On the other hand it looks almost too normal. Odd.
It could indicate bias on the part of the researchers. I haven’t read their methodology, but in my amateur study of languages, some languages have some interesting tricks for communication that don’t translate to English well or efficiently. If English was used as the baseline, then the study ma not incorporate some of the neat things other languages can do as points to measure.
Mandarin has a word particle to communicate “completed action”. This is used instead of conjugating verbs for tenses. Example: in English you might say:
“I went to the shop” 5 syllables
In Mandarin the literal translation back to English would be:
“I go to the shop [completed action]” 5 syllables
For the two measures listed of essentially Information Density and Speech Velocity, this benefit wouldn’t show up, but if you’re measure for something like Encoding and Decoding Burden (I’m making up these terms), then Mandarin could rank higher.
Looking up the article the baseline is French and English I’d say. So it might be biased, but I didn’t read the article and even if I did, I’m a chemical engineer so what do I know of this field.
Could be bias. But, I wonder if it could be because English has borrowed so much from other languages.
It’s also interesting that English and French look so similar in the graphs. Both, have been the de facto international language for a long time.
Wonder how Thai is the zipfile of languages.
My very casual understanding is that grammatical structure or gender isn’t really a thing, or articles for that matter, making it very contextual and tonal language so a zipfile isn’t even a bad metaphor.
However, in this case it seems like the human brain is the default Windows zip program.
It is multiplexed with five tones and a variety of different registers to signify relationship, status, and variable interplay between the two based on situation.
- University Thai language learner, linguist, and professional Thai reading, writing, speaking in Thailand for several years
Italian has a wildly different set than everyone else pretty much.
Thai is so efficient
Opposite. Look at the notes at the top of the graphs
Not as efficient as others in bits per second, but interestingly the syllable-to-bits ratio is tightly coupled.
Oh wait yeah you’re right.
It’s the fastest, but the least efficient actually!
It’s the slowest in speech and the one that conveys information the slowest too.
I’m so dumb. 😅
Hard to tell. Need something like “bits of information per syllable” to get at efficiency. Just eyeballing it, Vietnamese, English, and Cantonese seem most likely the most efficient.
Cantonese and Vietnamese make sense, as they’re are both tonal languages (along with Mandarin, Thai, Punjabi, and Cherokee apparently). English wastes tones on communicating stress or question vs statement.
So if I’m reading this right, French (closely followed by English) tends to convey the most info per unit time?
I think i read a study long ago, about the speed of transmiting information being faster in languagues of great empires. Sounds logical to me and matches English, French, Chinese.
Yes but they also utilize smell.
As a french, I’m very surprised by this, as when I see a text in French side-by-side with its English translation, the English version is usually shorter. It may be a difference between speech and text, but it’s still surprising.
I really thought the information density of French was pretty low, compared to English or Breton, for example.
spoiler
as a fr*nch 🤢
Spoiler didnt work ;)
Spoiler worked perfectly 🤮
Written French is slow (needs more words )
Spoken French IS faster
I think that’s due to English spelling vs French spelling. The latter uses a lot of letters to make a sound that could be recognized with simplified spelling. O = eaux
The graph is missing languages such as Portuguese and Arabic.
Syllables can vary in length. Japanese has very short syllables while English has rather long ones. Counting phonemes would make more sense
Inaccurate for Italian because 50% of the language is conveyed by auditory volume, hand gestures and body language … and espresso, lots and lots of espresso.
Turkish is also inaccurate because 25% of the language is in the eyes … those intense eyes where you can’t tell if someone is excited, energetic, full of life or psychotic / murderous.
hand gestures
🤌
That’s what I mean … just that hand gesture depending on who made it and in what circumstance just conveys a ton of information without saying a word.
It could mean … “hey that was fantastic spaghetti and the sauce was wonderful”
Or it could mean … “that was a ballsy move you did last night … imma gonna keep my eye on you and burn down your house next week”
Yeah but 30% of the information in French are the “uhhh’s” lmao
They solved that by not pronouncing half the language.
That was the issue I had with my elementary school spanish teacher. He spoke so fast that you just couldn’t latch onto anything. It just sounded like DDDDDDDDDDDDDDDDS aqui. DDDDDDDDDDDDDDDDRS agostos.
What produces the stretched graphs like Italian and German? What do these humps mean?
Variability in the length of words, loads of very short and very long words? Just a guess
That is likely part of it and also explains why languages like Japanese are more tightly grouped, as there is less spread in word length for Japanese versus English or Italian.
Both of those languages LOVE to compound their nouns - smashing smaller words into massive ones. Like the simple “pasta + asciutta = pastasciutta = dried pasta” or not simple “Donaudampfschifffahrtsgesellschaftskapitän = Danube steamship transport company captain”. All languages do it, but these do it with gusto.
Maybe they didn’t account for various factors like age or mood.
Moreover, Munic has 130 words per minute and dortmund has 180 words. There’s a ddifference in the dialect
https://preply.com/de/blog/sprechtempo-in-deutschland/ the numbers are just estimations and not a hard fact.
My hump my hump my hump, my lovely language lumps.
I would guess, if it’s solid empirical work behind this, that there’s just greater differences internally between German and Italian speakers than for many other languages. Having lived in both Germany and Italy, I do not struggle to believe this is the case.
This was one of the weirdest things I had to learn when I was learning spanish. The sounds are much faster but the information density was similar. For me as an english native speaker it felt like I was listening to a machine gun at first. Eventually I trained my ear and now both languages sound the same speed.
This is also why, to me, rapidly spoken natural Spanish and Japanese sound oddly similar if I hear it out of “the corner” of my ear, so to speak.
Which is funny cause I kinda speak Spanish lol
I recently had a conversation with a native Spanish speaker who lived in Japan and spoke Japanese fairly fluently. He said the exact same thing, it was surprising how similar they can be in this regard
Spanish and Japanese use the same sounds. For the most part, anyway; there are probably a few exceptions. This was unexpected and utterly blew my mind as a native Spanish speaker when I took Japanese lessons.
Take the longest, most complicated Japanese word. Write it out in romaji (Latin letters). And ask a native Spanish speaker to pronounce it. One who knows nothing of Japanese. They’ll pronounce it pretty much correctly. I was fascinated.
I would imagine this is because there is a ‘comfortable’ rate of information exchange in human converaation, and so each given language will be spoken at a pace that achieves this comfortable rate.
So it’s not that the syllable rate coincidentally results in the same information rate, but the opposite - the syllable rate adjusts to match the deaired information rate.
Interesting thought.
I’d add it’s probably also that 90%+ of conversation isn’t about “data transfer” in the technical sense, but relationship building. So information volume isn’t usually crucial.
Now let’s see this work done in technical fields, especially change management, maintenance, emergency services, etc, where time is crucial. Those environments tend to have very “coded” language, so we don’t have to say a paragraph whenever we call for a very specific function/tool/action.
I suspect the languages would still have similar curves, but the data rates would increase.
I believe the percentage for information exchange is a bit higher, even in everyday life. I mean we also socialize, talk about the weather etc. But many times I open my mouth, I actually want to convey some information or gather some… That probably varies widely between cultures (and individual people and rhe exact social setting). I read some people like to chat with their cashiers while others don’t. And for relationship building we also have body language etc so lots of that doesn’t even need verbal language.
I am pretty skeptical about these results in general. I would like to see the original research paper, but they usually
- write the text to be read in English, then translate them into the target languages.
- recurit test participants from US university campuses.
And then there’s the question of how do you measure the amount of information conveyed in natural languages using bits…
Yeah, the results are mostly likely very skewed.
There’s always Google Scholar.
So I did a quick pass through the paper, and I think it’s more or less bullshit. To clarify, I think the general conclusion (different languages have similar information densities) is probably fine. But the specific bits/s numbers for each language are pretty much garbage/meaningless.
First of all, speech rates is measured in number of canonical syllables, which is a) unfair to non-syllabic languages (e.g. (arguably) Japanese), b) favours (in terms of speech rate) languages that omit syllables a lot. (like you won’t say “probably” in full, you would just say something like “prolly”, which still counts as 3 syllables according to this paper).
And the way they calculate bits of information is by counting syllable bigrams, which is just… dumb and ridiculous.
I take your point without complaint, but I still think you’re an alien for saying “prolly”
I mean, probs. It’s right there. Use that if you have to
it’s pro^b - ly
Alright, but dismissing the study as “pretty much bullshit" based on a quick read-through seems like a huge oversimplification. Using canonical syllables as a measure is actually a widely accepted linguistic standard, designed precisely to make fair comparisons across languages with different structures, including languages like Japanese. It’s not about unfairly favoring any language but creating a consistent baseline, especially when looking at large, cross-linguistic patterns.
And on the syllable omission point, like “probably” vs. “prolly," I mean, sure, informal speech varies, but the study is looking at overall trends in speech rate and information density, not individual shortcuts in casual conversation. Those small variations certainly don’t turn the broader findings into bullshit.
As for the bigram approach, it’s a reasonable proxy to capture information density. They’re not trying to recreate every phonological or grammatical nuance; that would be way beyond the scope and would lose sight of the larger picture. Bigrams offer a practical, statistically valid method for comparing across languages without having to delve into the specifics of every syllable sequence in each language.
This isn’t about counting every syllable perfectly but showing that despite vast linguistic diversity, there’s an overarching efficiency in how languages encode information. The study reflects that and uses perfectly acceptable methods to do so.
Well I did clarify I agree that the overarching point of this paper is probably fine…
widely accepted linguistic standard
I am not a linguist so apologise for my ignorance about how things are usually done. (Also, thanks for educating me.) But on the other hand just because it is the accepted way doesn’t mean it is right in this case. Especially when you consider the information rate is also calculated from syllables.
syllable bigrams
Ultimately this just measures how quickly the speaker can produce different combinations of sounds, which is definitely not what most people would envision when they hear “information in language”. For linguists who are familiar with the methodology, this might be useful data. But the general public will just get the wrong idea and make baseless generalisations - as evidenced by comments under this post. All in all, this is bad science communication.
But the general public will just get the wrong idea and make baseless generalisations - as evidenced by comments under this post. All in all, this is bad science communication.
Perhaps, but to be clear, that’s on The Economist, not the researchers or scholarship. Your criticisms are valid to point out, but they aren’t likely to be significant enough to change anything meaningful in the final analysis. As far as the broad conclusions of the paper, I think the visualization works fine.
What you’re asking for in terms of methods that will capture some of the granularity you reference would need to be a separate study. And that study would probably not be a corrective to this paper. Rather, it would serve to “color between the lines” that this study establishes.
This conjecture explains the results surprisingly well. If the original was written in French, which then got translated to English, which was then used as the basis of translation for the other languages that would explain the results entirely.













{kind=link}